什麼是 Scraper Chain 擷取流程? #
Scraper Chain 擷取流程,是代表允許透過連接兩個 Scraper 來幫助您收集詳細資訊:一個 Scraper 收集商品列表,另一個 Scraper 從每個商品的頁面中提取具體細節。這種方法可讓您在同一網站的多個頁面上建立全面的資料集。
Scraper Chain 的常見情境 – 電商競品產品分析
1. 建立 Scraper A 從類別頁面收集產品信息,包括名稱、價格和 URL。
2. 建立 Scraper B 造訪每個產品的 URL 詳情頁面,收集規格、評論、星等、價格等全面資訊。
透過 Scraper Chain 將有助於跨產品類別進行競爭分析和價格監控。
Scraper Chain 的常見情境 – 房地產市場調查
1. 建立 Scraper A 從房源清單頁面,取得價格、地點等基本資訊。
2. 建立 Scarper B 造訪各個房源頁面,收集房源規格、配套設施、經紀人資訊、照片和歷史記錄。
透過 Scraper Chain 將有助於建構全面的房源市場分析。
如何從清單及其相關詳細資料頁面中提取資料? (擷取流程) #
Scraper Chain 能連接兩個 Scrapers:一個用於擷取列表每一個產品的 URLs,另一個用於從每個產品詳細頁面擷取詳細信息,便能獲得完整的數據集。
詳細可以參考 What is Scraper Chain
如何執行批次任務?
批次執行在 Scraper Chain 有兩種作法:
1. 手動輸入 Multiple URLs:使用此選項可以一次處理所有擷取的連結。
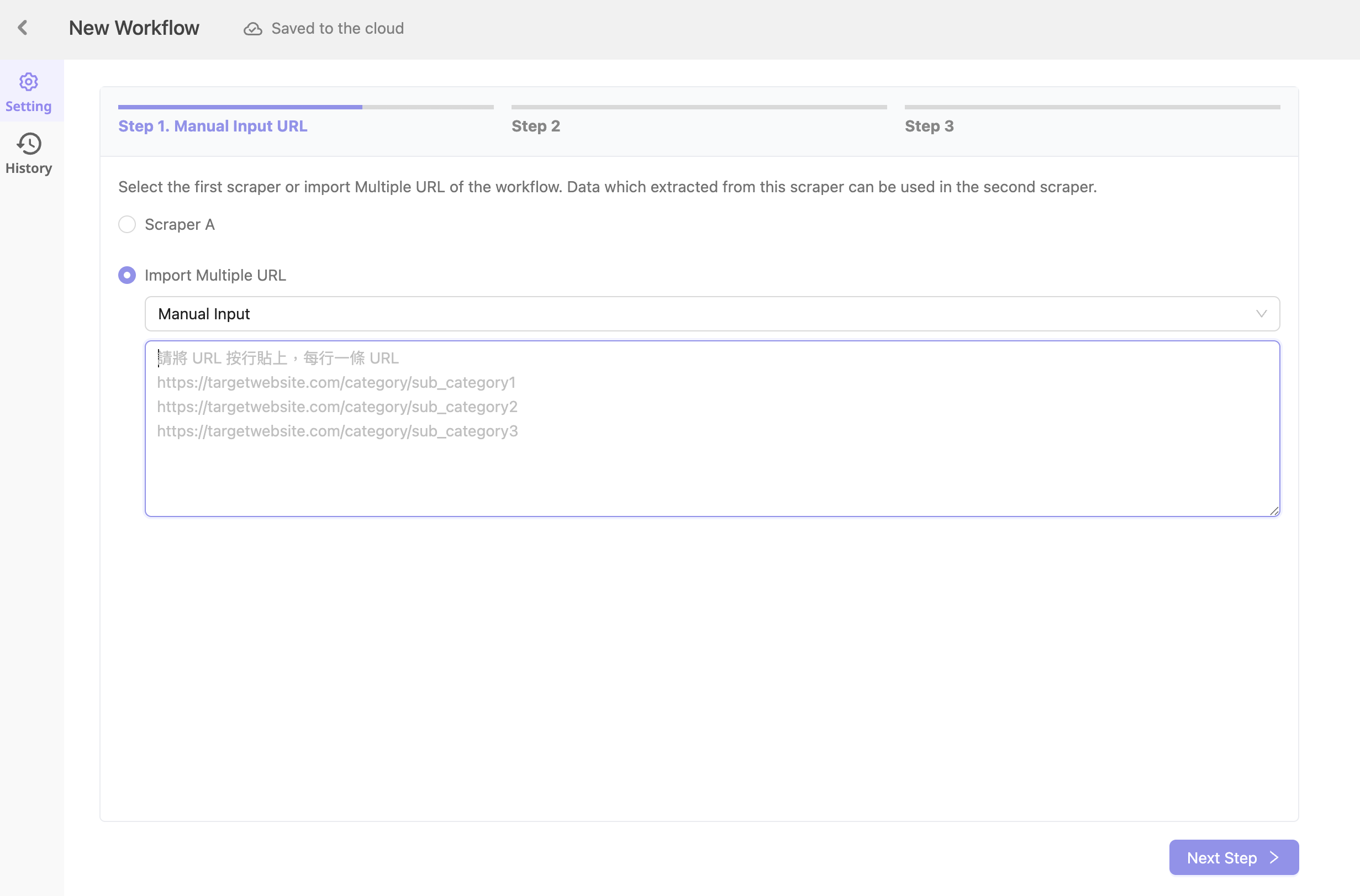
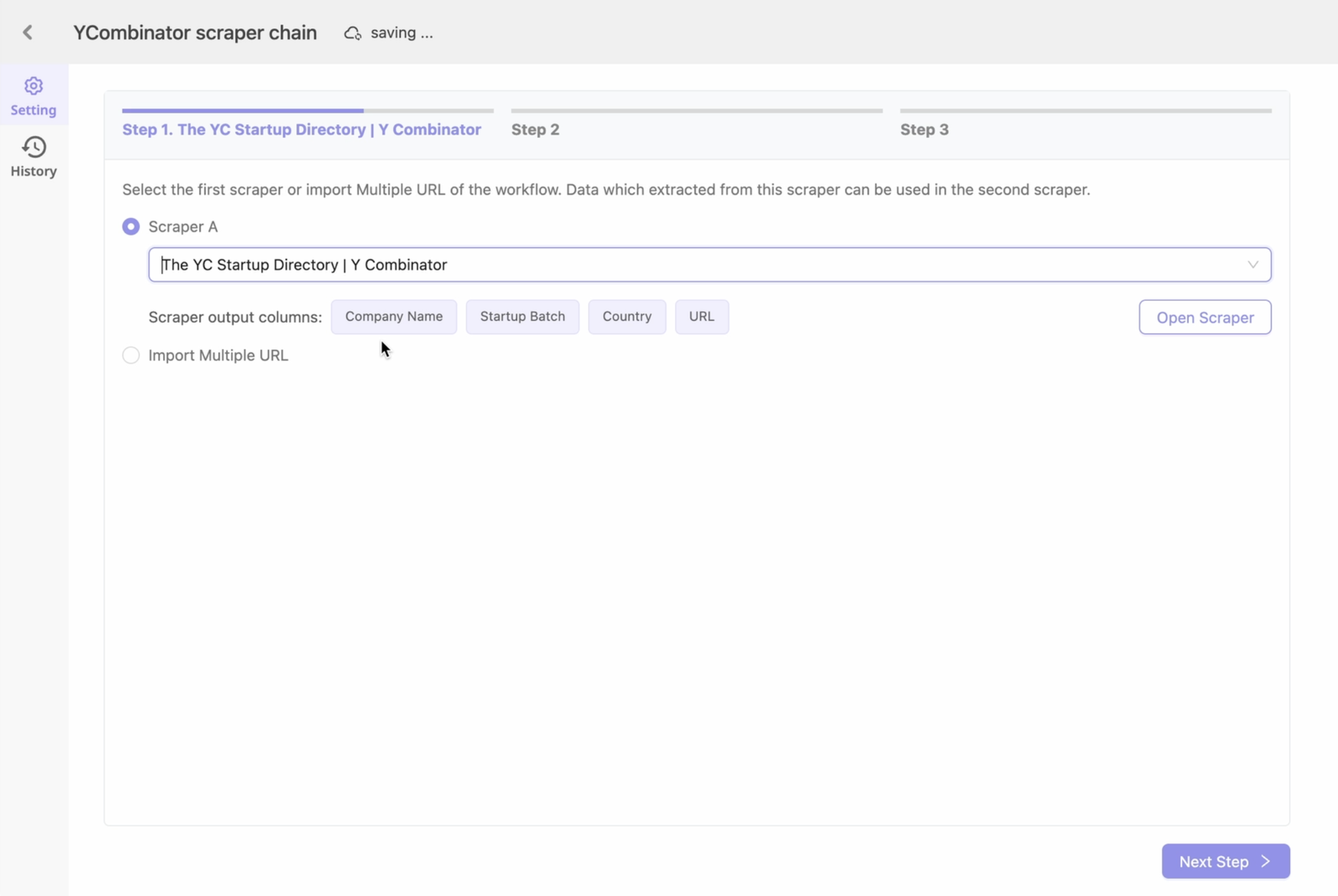
2. 利用第一個 Scraper 擷取的 URLs:自動連接清單 Scraper A 和詳細資訊 Scraper B,此選項也最適合需要定期更新的持續抓取任務。
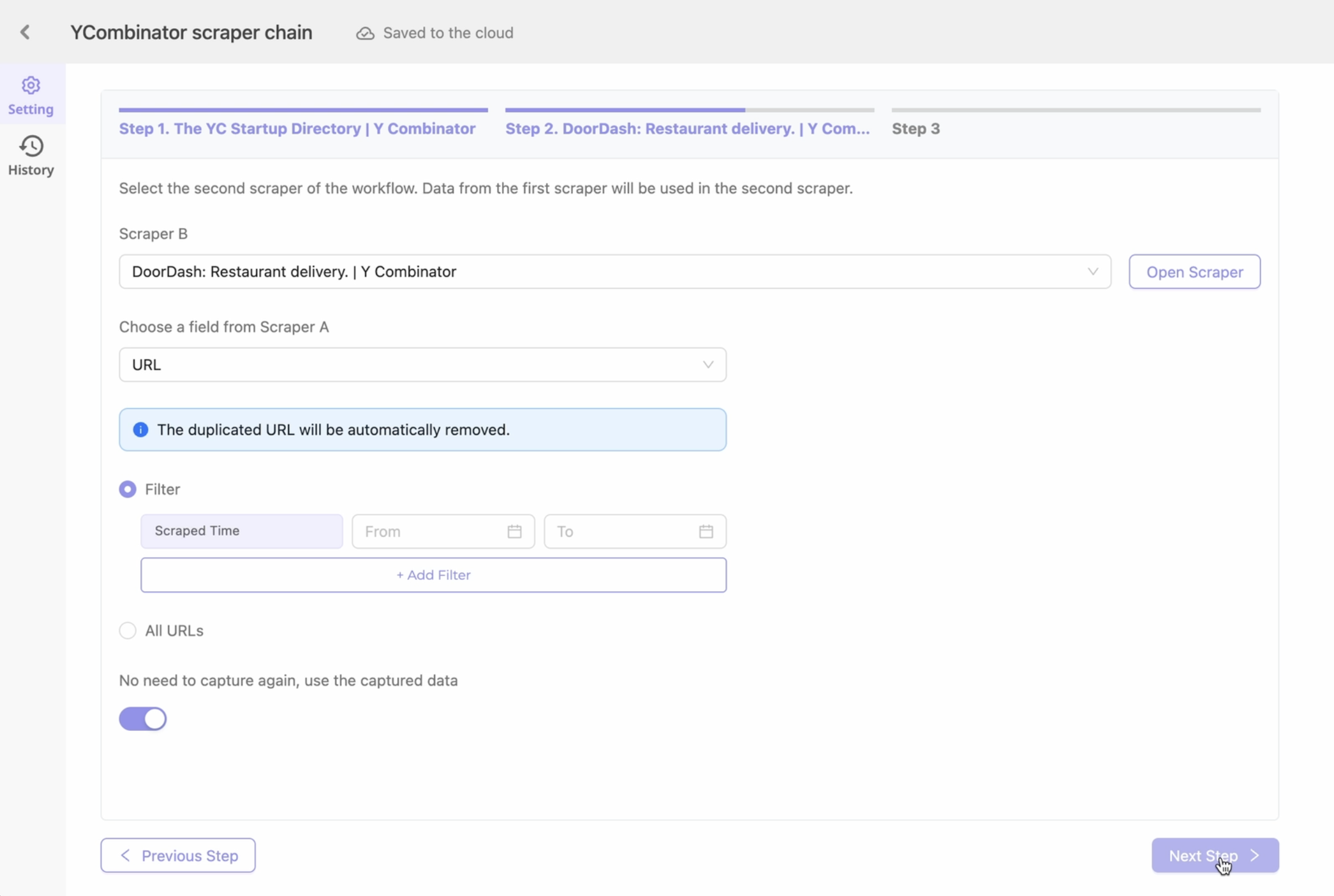
完成 Step1 的設定後,在 Step2 下方可以設定擷取的時間區間、自訂想要擷取或排除的內容,也可以設定無需再次擷取重複數據。
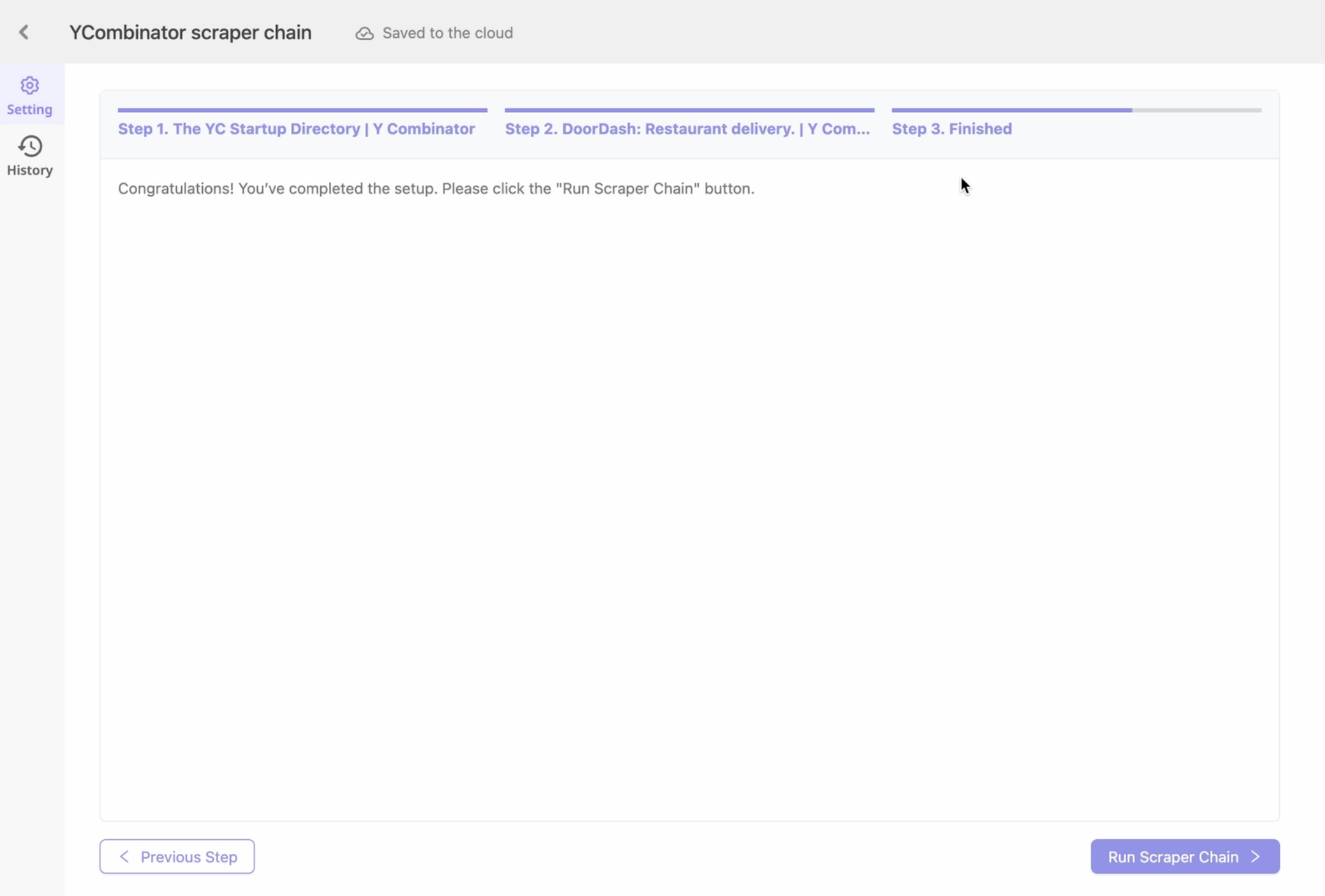
Step3 設定完成後點選右下方 “Run Scraper Chain” 按鈕即可。